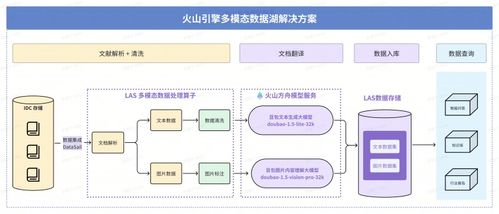
在人工智能與高性能計算深度融合的時代,科學研究正經(jīng)歷一場深刻的數(shù)據(jù)革命。面對生物醫(yī)藥、材料科學等領域爆炸式增長的多模態(tài)、高維度數(shù)據(jù),傳統(tǒng)的數(shù)據(jù)處理與分析模式已難以滿足高效、精準的科研需求。火山引擎多模態(tài)數(shù)據(jù)湖解決方案在深勢科技的成功落地與應用,為解決這一核心挑戰(zhàn)提供了創(chuàng)新范式,顯著提升了科研數(shù)據(jù)處理與價值挖掘的整體效能。
深勢科技作為AI for Science(科學智能)領域的領軍企業(yè),致力于運用人工智能與分子模擬算法,為藥物研發(fā)、材料設計等復雜科研問題提供解決方案。其科研工作流天然涉及海量的分子結構數(shù)據(jù)、模擬軌跡、物性參數(shù)、文獻文本及圖像等多源異構數(shù)據(jù)。如何高效存儲、管理、關聯(lián)并分析這些多模態(tài)數(shù)據(jù),打通從數(shù)據(jù)到洞察的“最后一公里”,是提升研發(fā)效率與創(chuàng)新成功率的關鍵。
火山引擎多模態(tài)數(shù)據(jù)湖的引入,為深勢科技構建了統(tǒng)一的科研數(shù)據(jù)基座。該方案的核心優(yōu)勢在于:
- 統(tǒng)一的存儲與元數(shù)據(jù)管理:打破了過去不同類型數(shù)據(jù)存儲于孤立系統(tǒng)(如對象存儲用于軌跡文件、數(shù)據(jù)庫用于結構化結果)的藩籬。數(shù)據(jù)湖提供了一個中心化的存儲池,并通過精細的元數(shù)據(jù)管理,將分子ID、模擬參數(shù)、實驗條件、文獻來源等信息進行有效關聯(lián),實現(xiàn)了數(shù)據(jù)資產(chǎn)的全局可視與可理解。
- 強大的多模態(tài)數(shù)據(jù)處理能力:針對科學數(shù)據(jù)的特點,該數(shù)據(jù)湖方案集成了高性能計算框架與數(shù)據(jù)處理引擎。它能夠無縫銜接深勢科技的分子動力學模擬等計算任務,自動攝取和預處理產(chǎn)生的TB甚至PB級軌跡數(shù)據(jù);支持對文本(科研文獻)、圖譜(分子結構圖)等進行特征提取與向量化,為后續(xù)的AI模型訓練與分析奠定基礎。
- 高效的分析與協(xié)同平臺:基于數(shù)據(jù)湖,研究人員可以運用統(tǒng)一的查詢語言或接口,跨模態(tài)地關聯(lián)分析數(shù)據(jù)。例如,快速檢索具有特定物性的所有分子及其相關的模擬條件與文獻證據(jù)。這不僅加速了科學發(fā)現(xiàn)的過程,也促進了不同團隊、不同學科背景研究人員之間的數(shù)據(jù)共享與協(xié)作,避免了重復工作和數(shù)據(jù)孤島。
- 彈性可擴展的云原生架構:依托火山引擎的云計算基礎設施,該數(shù)據(jù)湖具備極致的彈性擴展能力,能夠根據(jù)科研項目計算任務的數(shù)據(jù)吞吐需求,動態(tài)調配存儲與計算資源,實現(xiàn)成本與性能的最優(yōu)平衡,尤其適用于突發(fā)性的大規(guī)模模擬計算場景。
此次合作的落地,其價值已初步顯現(xiàn)。對深勢科技而言,數(shù)據(jù)處理管線得以自動化與標準化,研究人員從繁瑣的數(shù)據(jù)搬運、格式轉換和基礎管理中解放出來,更專注于核心的算法創(chuàng)新與科學假設驗證。數(shù)據(jù)處理周期顯著縮短,數(shù)據(jù)資產(chǎn)的復用率和價值密度大幅提升,為新藥研發(fā)管線的高效推進提供了堅實的數(shù)據(jù)驅動支撐。
火山引擎多模態(tài)數(shù)據(jù)湖與深勢科技AI for Science平臺的深度融合,將持續(xù)演化。它不僅是存儲與計算的容器,更將成長為匯聚科研知識、孵化智能模型的“數(shù)字反應堆”。通過持續(xù)積累高質量、結構化的科學數(shù)據(jù)資產(chǎn),并利用AI進行深度挖掘與生成,有望在全新的分子發(fā)現(xiàn)、性質預測、反應路徑設計等方面取得突破,最終推動科學研究范式的根本性變革。
此次成功實踐,也為面臨類似多模態(tài)、大數(shù)據(jù)挑戰(zhàn)的生物制藥、能源材料、計算化學等廣大科研與工業(yè)領域,提供了可借鑒的數(shù)字化轉型路徑。它證明,一個設計優(yōu)良的數(shù)據(jù)湖,能夠成為釋放數(shù)據(jù)潛能、加速科技創(chuàng)新的核心基礎設施。